ड्रिसियनपेज के साथ कैपसॉल्वर कैसे एकीकृत करें: सीमलेस CAPTCHA हल करें

Rajinder Singh
Deep Learning Researcher

1. परिचय
वेब ऑटोमेशन डेटा संग्रहण, परीक्षण और विभिन्न व्यावसायिक ऑपरेशन के लिए आवश्यक हो गया है। हालांकि, आधुनिक वेबसाइटें ड्रिस्शनपेज और कैपसॉल्वर के संयोजन के साथ वेब ऑटोमेशन के लिए एक शक्तिशाली समाधान प्रदान करते हैं:
- DrissionPage: सेलेनियम/वेबड्राइवर साइनेचर के बिना क्रोमियम ब्राउज़र को नियंत्रित करने वाला एक पायथन-आधारित वेब ऑटोमेशन टूल
- CapSolver: क्लाउडफ़्लेर टर्नस्टाइल, reCAPTCHA आदि के साथ काम करने वाली एआई-आधारित कैपचा हल करने वाली सेवा
इन टूल्स के संयोजन से वेब ऑटोमेशन के ब्राउज़र ड्राइवर की पहचान और कैपचा चुनौतियों के बिना बिना किसी मानवीय हस्तक्षेप के समाधान के साथ निरंतर ऑटोमेशन संभव हो जाता है।
1.1. एकीकरण लक्ष्य
इस गाइड आपके तीन मुख्य लक्ष्य प्राप्त करने में मदद करेगा:
- WebDriver पहचान बचें - सेलेनियम/वेबड्राइवर साइनेचर के बिना ब्राउज़र के नेटिव नियंत्रण का उपयोग करें
- कैपचा स्वचालित रूप से हल करें - कैपसॉल्वर के API के साथ कैपचा चुनौतियों को हल करने के लिए एकीकरण करें
- मानव-जैसा व्यवहार बनाए रखें - क्रिया श्रृंखला के साथ बुद्धिमान कैपचा हल करें
2. DrissionPage क्या है?
DrissionPage पायथन-आधारित वेब ऑटोमेशन टूल है जो ब्राउज़र नियंत्रण के साथ HTTP मांग क्षमता के साथ जुड़ा हुआ है। सेलेनियम के विपरीत, यह वेबड्राइवर पर निर्भर नहीं करता है, इसलिए इसे पहचाना जाना कठिन होता है।
2.1. मुख्य विशेषताएं
- वेबड्राइवर की आवश्यकता नहीं होती है - वेबड्राइवर के बिना क्रोमियम ब्राउज़र को नेटिव रूप से नियंत्रित करें
- द्वि-मोड संचालन - ब्राउज़र ऑटोमेशन (d मोड) के साथ HTTP मांग के संयोजन (s मोड)
- सरल तत्व स्थान निर्धारण - तत्व के लिए अंतर्निहित सिंटैक्स
- एफ़्रेम के बीच परिवर्तन - एफ़्रेम के बिना नेस्टेड सामग्री में तत्व का पता लगाएं
- मल्टी-टैब समर्थन - एक साथ कई टैब के संचालन
- क्रिया श्रृंखला - माउस और कीबोर्ड क्रियाओं के साथ श्रृंखला बनाएं
- निर्मित वाइट्स - अस्थिर नेटवर्क के लिए स्वचालित पुनर्प्रयास तंत्र
2.2. स्थापना
bash
# DrissionPage स्थापित करें
pip install DrissionPage
# कैपसॉल्वर API के लिए requests लाइब्रेरी स्थापित करें
pip install requests2.3. मूल उपयोग
python
from DrissionPage import ChromiumPage
# ब्राउज़र अनुभव बनाएं
page = ChromiumPage()
# URL पर जाएं
page.get('https://wikipedia.org')
# तत्वों को खोजें और बातचीत करें
page('#search-input').input('हैलो वर्ल्ड')
page('#submit-btn').click()3. CapSolver क्या है?
CapSolver एक एआई-आधारित स्वचालित कैपचा हल करने वाली सेवा है जो विस्तृत कैपचा प्रकारों के साथ काम करती है। यह आपको कैपचा चुनौतियों को जमा करने और कुछ सेकंड में समाधान प्राप्त करने के लिए एक सरल API प्रदान करता है।
3.1. समर्थित कैपचा प्रकार
- क्लाउडफ़्लेर टर्नस्टाइल - सबसे आम आधुनिक एंटी-बॉट चुनौति
- क्लाउडफ़्लेर चुनौति
- reCAPTCHA v2 - छवि-आधारित और अदृश्य वेरिएंट
- reCAPTCHA v3 - स्कोर-आधारित पुष्टि
- AWS WAF - अमेज़न वेब सेवाएं कैपचा
- और बहुत कुछ...
3.2. CapSolver के साथ शुरू करें
- capsolver.com पर पंजीकरण करें
- अपने खाते में धन जमा करें
- डैशबोर्ड से अपना API की प्राप्त करें
3.3. API एंडपॉइंट
- सर्वर A:
https://api.capsolver.com - सर्वर B:
https://api-stable.capsolver.com
4. एकीकरण से पहले की चुनौतियां
कैपसॉल्वर के साथ ड्रिस्शनपेज के संयोजन से पहले, वेब ऑटोमेशन कई दुखद चुनौतियों का सामना करता रहा है:
| चुनौति | प्रभाव |
|---|---|
| WebDriver पहचान | सेलेनियम स्क्रिप्ट तुरंत ब्लॉक कर दिया जाता है |
| कैपचा चुनौतियां | मैनुअल समाधान की आवश्यकता होती है, ऑटोमेशन तोड़ देता है |
| iframe जटिलता | एम्बेडेड सामग्री से बातचीत करना कठिन होता है |
| मल्टी-टैब संचालन | जटिल टैब स्विचिंग तंत्र की आवश्यकता होती है |
ड्रिस्शनपेज + कैपसॉल्वर एकीकरण एक ही वर्कफ़्लो में इन सभी चुनौतियों का समाधान करता है।
5. एकीकरण विधियां
5.1. API एकीकरण (सुझाई गई)
API एकीकरण दृष्टिकोण कैपचा हल करने प्रक्रिया के पूर्ण नियंत्रण प्रदान करता है और किसी भी कैपचा प्रकार के साथ काम करता है।
5.1.1. सेटअप आवश्यकताएं
bash
pip install DrissionPage requests5.1.2. मुख्य एकीकरण पैटर्न
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "आपका API की"
CAPSOLVER_API = "https://api.capsolver.com"
def create_task(task_payload: dict) -> str:
"""कैपचा हल करने के कार्य को बनाएं और कार्य पहचानकर्ता लौटाएं।"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": task_payload
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"कैपसॉल्वर त्रुटि: {result.get('errorDescription')}")
return result["taskId"]
def get_task_result(task_id: str, max_attempts: int = 120) -> dict:
"""समाधान या समय सीमा समाप्त होने तक कार्य परिणाम के लिए पॉल करें।"""
for _ in range(max_attempts):
response = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]
elif result.get("status") == "failed":
raise Exception(f"कार्य विफल: {result.get('errorDescription')}")
time.sleep(1)
raise TimeoutError("कैपचा हल करने में समय सीमा समाप्त हो गई")
def solve_captcha(task_payload: dict) -> dict:
"""कैपचा हल करने की पूर्ण प्रक्रिया पूरी करें।"""
task_id = create_task(task_payload)
return get_task_result(task_id)5.2. ब्राउज़र एक्सटेंशन
आप कैपसॉल्वर ब्राउज़र एक्सटेंशन के साथ ड्रिस्शनपेज का उपयोग कर सकते हैं जो एक अधिक हस्तक्षेप रहित दृष्टिकोण प्रदान करता है।
5.2.1. स्थापना चरण
- capsolver.com/en/extension से कैपसॉल्वर एक्सटेंशन डाउनलोड करें
- एक्सटेंशन फ़ाइलें निकालें
- एक्सटेंशन के
config.jsफ़ाइल में अपने API की कॉन्फ़िगरेशन करें:
javascript
// एक्सटेंशन फ़ोल्डर में, संपादित करें: assets/config.js
var defined = {
apiKey: "आपका कैपसॉल्वर API की", // अपने वास्तविक API की बदलें
enabledForBlacklistControl: false,
blackUrlList: [],
enabledForRecaptcha: true,
enabledForRecaptchaV3: true,
enabledForTurnstile: true,
// ... अन्य सेटिंग्स
}- इसे DrissionPage में लोड करें:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.add_extension('/path/to/capsolver-extension')
page = ChromiumPage(co)
# एक्सटेंशन कैपचा को स्वचालित रूप से पहचानेगा और हल करेगानोट: एक्सटेंशन कैपचा को स्वचालित रूप से हल कर सकता है, लेकिन इसके लिए एक वैध API की कॉन्फ़िगरेशन आवश्यक है।
6. कोड उदाहरण
6.1. क्लाउडफ़्लेर टर्नस्टाइल हल करें
क्लाउडफ़्लेर टर्नस्टाइल एक सबसे आम कैपचा चुनौति है। यहां इसके हल करने का तरीका है:
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "आपका API की"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_turnstile(site_key: str, page_url: str) -> str:
"""क्लाउडफ़्लेर टर्नस्टाइल को हल करें और टोकन लौटाएं।"""
# कार्य बनाएं
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"त्रुटि: {result.get('errorDescription')}")
task_id = result["taskId"]
# परिणाम के लिए पॉल करें
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
elif result.get("status") == "failed":
raise Exception(f"विफल: {result.get('errorDescription')}")
time.sleep(1)
def main():
लक्ष्य_पृष्ठ = "https://आपका-लक्ष्य-साइट.com"
टर्नस्टाइल_साइट_की = "0x4XXXXXXXXXXXXXXXXX" # पृष्ठ के स्रोत में ढूंढें
# ब्राउज़र अनुभव बनाएं
page = ChromiumPage()
page.get(लक्ष्य_पृष्ठ)
# टर्नस्टाइल लोड होने के लिए प्रतीक्षा करें
page.wait.ele_displayed('input[name="cf-turnstile-response"]', timeout=10)
# कैपचा हल करें
टोकन = solve_turnstile(टर्नस्टाइल_साइट_की, लक्ष्य_पृष्ठ)
print(f"टर्नस्टाइल टोकन प्राप्त किया: {टोकन[:50]}...")
# टोकन को जावास्क्रिप्ट के माध्यम से निवेश करें
page.run_js(f'''
document.querySelector('input[name="cf-turnstile-response"]').value = "{टोकन}";
// यदि उपलब्ध हो तो कॉलबैक ट्रिगर करें
const callback = document.querySelector('[data-callback]');
if (callback) {{
const callbackName = callback.getAttribute('data-callback');
if (window[callbackName]) {{
window[callbackName]('{टोकन}');
}}
}}
''')
# फॉर्म जमा करें
page('button[type="submit"]').click()
page.wait.load_start()
print("टर्नस्टाइल को सफलतापूर्वक पार कर गए!")
if __name__ == "__main__":
main()6.2. reCAPTCHA v2 (साइट की स्वचालित रूप से पहचानें)
इस उदाहरण में पृष्ठ से साइट की स्वचालित रूप से पहचाना जाता है - कोई मैनुअल कॉन्फ़िगरेशन की आवश्यकता नहीं होती है:
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "आपका API की"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v2(site_key: str, page_url: str) -> str:
"""reCAPTCHA v2 को हल करें और टोकन लौटाएं।"""
# कार्य बनाएं
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"त्रुटि: {result.get('errorDescription')}")
task_id = result["taskId"]
print(f"कार्य बनाया गया: {task_id}")
# परिणाम के लिए पॉल करें
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"विफल: {result.get('errorDescription')}")
time.sleep(1)
def main():
# केवल URL प्रदान करें - साइट की स्वचालित रूप से पहचानी जाएगी
लक्ष्य_पृष्ठ = "https://www.google.com/recaptcha/api2/demo"
# ब्राउज़र कॉन्फ़िगर करें
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
print("ब्राउज़र शुरू कर रहा है...")
page = ChromiumPage(co)
try:
page.get(लक्ष्य_पृष्ठ)
time.sleep(2)
# पृष्ठ से साइट की स्वचालित रूप से पहचानें
recaptcha_div = page('.g-recaptcha')
if not recaptcha_div:
print("पृष्ठ पर कोई reCAPTCHA नहीं मिला!")
return
site_key = recaptcha_div.attr('data-sitekey')
print(f"स्वचालित रूप से पहचानी गई साइट की: {site_key}")
# कैपचा हल करें
print("reCAPTCHA v2 हल कर रहा है...")
token = solve_recaptcha_v2(site_key, लक्ष्य_पृष्ठ)
print(f"टोकन प्राप्त किया: {token[:50]}...")
# टोकन निवेश करें
page.run_js(f'''
var responseField = document.getElementById('g-recaptcha-response');
responseField.style.display = 'block';
responseField.value = '{token}';
''')
print("टोकन निवेश किया गया!")
# फॉर्म जमा करें
submit_btn = page('#recaptcha-demo-submit') or page('input[type="submit"]') or page('button[type="submit"]')
if submit_btn:
submit_btn.click()
time.sleep(3)
print("फॉर्म जमा कर दिया!")
print(f"वर्तमान URL: {page.url}")
print("सफलता!")
finally:
page.quit()
if __name__ == "__main__":
main()खुद इसे परीक्षण करें:
bash
python recaptcha_demo.pyइससे गूगल के reCAPTCHA डेमो पृष्ठ खुलेगा, साइट की स्वचालित रूप से पहचानेगा, कैपचा हल करेगा और फॉर्म जमा करेगा।
6.3. reCAPTCHA v3 हल करें
reCAPTCHA v3 स्कोर-आधारित है और उपयोगकर्ता अंतरक्रिया की आवश्यकता नहीं होती है। आपको कार्य पैरामीटर बताना होगा।
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "आपका API की"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v3(
site_key: str,
page_url: str,
action: str = "verify",
min_score: float = 0.7
) -> str:
"""निर्दिष्ट कार्य और न्यूनतम स्कोर के साथ reCAPTCHA v3 हल करें।"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
"pageAction": action,
"minScore": min_score
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"त्रुटि: {result.get('errorDescription')}")
task_id = result["taskId"]
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"विफल: {result.get('errorDescription')}")
time.sleep(1)
def main():
लक्ष्य_पृष्ठ = "https://आपका-लक्ष्य-साइट.com"
recaptcha_v3_key = "6LcXXXXXXXXXXXXXXXXXXXXXXXXX"
# v3 के लिए हेडलेस ब्राउज़र सेट करें
co = ChromiumOptions()
co.headless()
page = ChromiumPage(co)
page.get(लक्ष्य_पृष्ठ)
# "खोज" कार्य के साथ reCAPTCHA v3 हल करें
print("reCAPTCHA v3 हल कर रहा है...")
token = solve_recaptcha_v3(
recaptcha_v3_key,
लक्ष्य_पृष्ठ,
action="खोज",
min_score=0.9 # उच्च स्कोर के लिए अनुरोध करें
)
# टोकन के साथ कॉलबैक चलाएं
page.run_js(f'''
// यदि कॉलबैक फ़ंक्शन उपलब्ध है, तो इसे टोकन के साथ कॉल करें
if (typeof onRecaptchaSuccess === 'function') {{
onRecaptchaSuccess('{token}');
}}
''')
print("टंत्र चलाया गया!")
print(f"वर्तमान URL: {page.url}")
print("सफलता!")
if __name__ == "__main__":
main()ड्रिसनपेज + कैपसॉल्वर: उन्नत वेब ऑटोमेशन के साथ कैप्चा बाउंस तकनीकें
ड्रिसनपेज और कैपसॉल्वर के संयोजन ने वेब ऑटोमेशन के लिए एक शक्तिशाली टूलकिट बनाया है:
- ड्रिसनपेज ड्राइवर के बिना ब्राउज़र ऑटोमेशन को हैंडल करता है
- कैपसॉल्वर कैप्चा को आईएएस-आधारित समाधान के साथ हैंडल करता है
- एक साथ वे पूरी तरह मानव जैसी ऑटोमेशन की अनुमति देते हैं
क्या आप वेब स्क्रैपर, ऑटोमेटेड टेस्टिंग प्रणाली या डेटा एकत्रीकरण पाइपलाइन बना रहे हैं, इस संयोजन के साथ आपको आवश्यक विश्वसनीयता और छिपावट मिलती है।
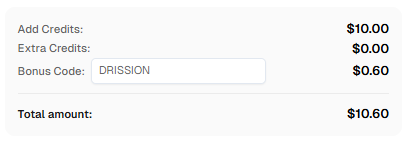
बोनस: कैपसॉल्वर पर पंजीकरण करते समय कोड
DRISSIONका उपयोग करें ताकि बोनस क्रेडिट मिले!
8. निष्कर्ष
ड्रिसनपेज और कैपसॉल्वर के संयोजन ने वेब ऑटोमेशन के लिए एक शक्तिशाली टूलकिट बनाया है:
- ड्रिसनपेज ड्राइवर के बिना ब्राउज़र ऑटोमेशन को हैंडल करता है
- कैपसॉल्वर कैप्चा को आईएएस-आधारित समाधान के साथ हैंडल करता है
- एक साथ वे पूरी तरह मानव जैसी ऑटोमेशन की अनुमति देते हैं
क्या आप वेब स्क्रैपर, ऑटोमेटेड टेस्टिंग प्रणाली या डेटा एकत्रीकरण पाइपलाइन बना रहे हैं, इस संयोजन के साथ आपको आवश्यक विश्वसनीयता और छिपावट मिलती है।
बोनस: कैपसॉल्वर पर पंजीकरण करते समय कोड
DRISSIONका उपयोग करें ताकि बोनस क्रेडिट मिले!
9. एफ़क्यू (FAQ)
9.1. ड्रिसनपेज के बजाय सेलेनियम क्यों चुनें?
ड्रिसनपेज ड्राइवर का उपयोग नहीं करता है, इसका मतलब है:
- क्रोमड्राइवर डाउनलोड करने या अपडेट करने की आवश्यकता नहीं है
- सामान्य ड्राइवर डिटेक्शन सिग्नेचर से बचें
- बेहतर एपीआई के साथ बिल्ट-इन वेट्स
- बेहतर प्रदर्शन और संसाधन उपयोग
- क्रॉस-फ्रेम तत्व स्थान निर्धारण के लिए मूल समर्थन
9.2. इस एकीकरण के साथ कौन से कैप्चा प्रकार सबसे अच्छा काम करते हैं?
कैपसॉल्वर सभी प्रमुख कैप्चा प्रकारों का समर्थन करता है। क्लाउडफ़ेयर टर्नस्टाइल और reCAPTCHA v2/v3 के उच्चतम सफलता दर हैं। एकीकरण किसी भी कैप्चा के साथ सुचारू रूप से काम करता है जिसका समर्थन कैपसॉल्वर करता है।
9.3. क्या मैं हेडलेस मोड में इसका उपयोग कर सकता हूं?
हां! ड्रिसनपेज हेडलेस मोड का समर्थन करता है। reCAPTCHA v3 और टोकन-आधारित कैप्चा के लिए, हेडलेस मोड पूरी तरह से काम करता है। v2 दृश्य कैप्चा के लिए, हेडेड मोड बेहतर परिणाम प्रदान कर सकता है।
9.4. कैप्चा के लिए साइट कुंजी कैसे खोजें?
पेज स्रोत में देखें:
- टर्नस्टाइल:
data-sitekeyलक्षण याcf-turnstileतत्व - reCAPTCHA:
g-recaptchaडिव परdata-sitekeyलक्षण
9.5. क्या कैप्चा समाधान विफल हो जाता है?
आम समाधान:
- अपने API कुंजी और बैलेंस की पुष्टि करें
- सुनिश्चित करें कि साइट कुंजी सही है
- जांचें कि पेज URL वही है जहां कैप्चा दिखाई देता है
- v3 के लिए, कार्य पैरामीटर और न्यूनतम स्कोर को बदलने का प्रयास करें
- अंतराल के साथ रीट्राय लॉजिक के साथ लागू करें
9.6. क्या ड्रिसनपेज शैडो डीओएम को हैंडल कर सकता है?
हां! ड्रिसनपेज के पास ChromiumShadowElement वर्ग के माध्यम से शैडो डीओएम तत्वों के लिए बिल्ट-इन समर्थन है।
और देखें
web scrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
web scrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।